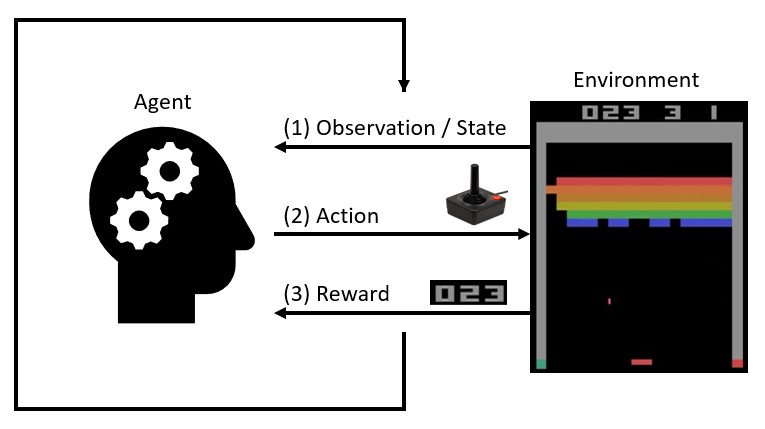
class Agent:
def __init__(self, **config):
self.config = config
self.n_actions = self.config["n_actions"]
self.state_shape = self.config["state_shape"]
self.batch_size = self.config["batch_size"]
self.gamma = self.config["gamma"]
self.initial_mem_size_to_train = self.config["initial_mem_size_to_train"]
torch.manual_seed(self.config["seed"])
if torch.cuda.is_available():
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.cuda.empty_cache()
torch.cuda.manual_seed(self.config["seed"])
torch.cuda.manual_seed_all(self.config["seed"])
self.device = torch.device("cuda")
else:
self.device = torch.device("cpu")
self.memory = ReplayMemory(self.config["mem_size"], self.config["alpha"], self.config["seed"])
self.v_min = self.config["v_min"]
self.v_max = self.config["v_max"]
self.n_atoms = self.config["n_atoms"]
self.support = torch.linspace(self.v_min, self.v_max, self.n_atoms).to(self.device)
self.delta_z = (self.v_max - self.v_min) / (self.n_atoms - 1)
self.offset = torch.linspace(0, (self.batch_size - 1) * self.n_atoms, self.batch_size).long() \
.unsqueeze(1).expand(self.batch_size, self.n_atoms).to(self.device)
self.n_step = self.config["n_step"]
self.n_step_buffer = deque(maxlen=self.n_step)
self.online_model = Model(self.state_shape, self.n_actions,
self.n_atoms, self.support, self.device).to(self.device)
self.target_model = Model(self.state_shape, self.n_actions,
self.n_atoms, self.support, self.device).to(self.device)
self.hard_update_target_network()
self.optimizer = optim.Adam(self.online_model.parameters(), lr=self.config["lr"], eps=self.config["adam_eps"])
def save(self, save_path, beta, episode=0):
model = {'online': self.online_model.state_dict(), 'beta': beta, 'min_episode': episode}
torch.save(model, save_path)
def load(self, load_path):
checkpoint = torch.load(load_path)
self.online_model.load_state_dict(checkpoint['online'])
self.hard_update_target_network()
params["beta"] = checkpoint['beta']
self.min_episode = 0
def plot_and_save(self,
episode,
episode_reward,
episode_loss,
episode_g_norm,
step,
beta,
episode_len,
show_result=False):
if is_ipython:
if not show_result:
display.display(plt.gcf())
display.clear_output(wait=True)
else:
display.display(plt.gcf())
self.rewards.append(episode_reward)
if len(self.rewards) > self.config["save_n_rewards"]:
self.rewards.pop(0)
self.avg_rewards.pop(0)
if len(self.rewards) > self.config["avg_window"]:
self.avg_rewards.append(np.mean(self.rewards[-self.config["avg_window"]:]))
else:
self.avg_rewards.append(0)
print(f'Episode: {episode}/{self.config["max_steps"]} ' \
f'| Step: {step} ' \
f'| Beta: {beta}' \
f'| Episode reward: {episode_reward} ' \
f'| Episode loss: {episode_loss}' \
f'| Episode G-Norm: {episode_g_norm}' \
f'| Episode Len: {episode_len}'
)
plt.figure(1)
if show_result:
plt.title('Result')
else:
plt.clf()
plt.title('Training...')
plt.xlabel('Episode')
plt.ylabel('Reward')
x_axis = range(max(1,episode-self.config["save_n_rewards"]+1),episode+1)
plt.plot(x_axis, self.rewards)
plt.plot(x_axis, self.avg_rewards)
plt.pause(0.001) # pause for plt update
if episode_reward >= self.best_reward:
self.best_reward = episode_reward
self.save(f'atari_trained_online_net_ep_{episode}_{episode_reward}.dat', beta, episode)
elif self.avg_rewards[-1] > self.best_avg_rewards:
self.best_avg_rewards = self.avg_rewards[-1]
self.save(f'atari_trained_online_net_avg_{episode}_{self.avg_rewards[-1]}.dat', beta, episode)
if show_result:
self.save('atari_trained_online_net.dat', beta, episode)
def choose_action(self, state):
state = np.expand_dims(state, axis=0)
state = torch.from_numpy(state).byte().to(self.device)
with torch.no_grad():
self.online_model.reset()
action = self.online_model.get_q_value(state).argmax(-1)
return action.item()
def store(self, state, action, reward, next_state, done):
"""Save I/O s to store them in RAM and not to push pressure on GPU RAM """
assert state.dtype == "uint8"
assert next_state.dtype == "uint8"
assert isinstance(reward, int)
assert isinstance(done, bool)
self.n_step_buffer.append((state, action, reward, next_state, done))
if len(self.n_step_buffer) < self.n_step:
return
reward, next_state, done = self.get_n_step_returns()
state, action, *_ = self.n_step_buffer.popleft()
self.memory.add(state, np.uint8(action), reward, next_state, done)
def soft_update_target_network(self, tau):
for target_param, local_param in zip(self.target_model.parameters(), self.online_model.parameters()):
target_param.data.copy_(tau * local_param.data + (1.0 - tau) * target_param.data)
# self.target_model.train()
for param in self.target_model.parameters():
param.requires_grad = False
def hard_update_target_network(self):
self.target_model.load_state_dict(self.online_model.state_dict())
# self.target_model.train()
for param in self.target_model.parameters():
param.requires_grad = False
def unpack_batch(self, batch):
batch = self.config["transition"](*zip(*batch))
states = torch.from_numpy(np.stack(batch.state)).to(self.device)
actions = torch.from_numpy(np.stack(batch.action)).to(self.device).view((-1, 1))
rewards = torch.from_numpy(np.stack(batch.reward)).to(self.device).view((-1, 1))
next_states = torch.from_numpy(np.stack(batch.next_state)).to(self.device)
dones = torch.from_numpy(np.stack(batch.done)).to(self.device).view((-1, 1))
return states, actions, rewards, next_states, dones
def train(self, beta):
if len(self.memory) < self.initial_mem_size_to_train:
return 0, 0 # as no loss
batch, weights, indices = self.memory.sample(self.batch_size, beta)
states, actions, rewards, next_states, dones = self.unpack_batch(batch)
weights = torch.from_numpy(weights).float().to(self.device)
with torch.no_grad():
self.online_model.reset()
self.target_model.reset()
q_eval_next = self.online_model.get_q_value(next_states)
selected_actions = torch.argmax(q_eval_next, dim=-1)
q_next = self.target_model(next_states)[range(self.batch_size), selected_actions]
projected_atoms = rewards + (self.gamma ** self.n_step) * self.support * (~dones)
projected_atoms = projected_atoms.clamp(min=self.v_min, max=self.v_max)
b = (projected_atoms - self.v_min) / self.delta_z
lower_bound = b.floor().long()
upper_bound = b.ceil().long()
lower_bound[(upper_bound > 0) * (lower_bound == upper_bound)] -= 1
upper_bound[(lower_bound < (self.n_atoms - 1)) * (lower_bound == upper_bound)] += 1
projected_dist = torch.zeros(q_next.size(), dtype=torch.float64).to(self.device)
projected_dist.view(-1).index_add_(0, (lower_bound + self.offset).view(-1),
(q_next * (upper_bound.float() - b)).view(-1))
projected_dist.view(-1).index_add_(0, (upper_bound + self.offset).view(-1),
(q_next * (b - lower_bound.float())).view(-1))
eval_dist = self.online_model(states)[range(self.batch_size), actions.squeeze().long()]
dqn_loss = -(projected_dist * torch.log(eval_dist + 1e-6)).sum(-1)
td_error = dqn_loss.abs() + 1e-6
self.memory.update_priorities(indices, td_error.detach().cpu().numpy())
dqn_loss = (dqn_loss * weights).mean()
self.optimizer.zero_grad()
dqn_loss.backward()
grad_norm = torch.nn.utils.clip_grad_norm_(self.online_model.parameters(), self.config["clip_grad_norm"])
self.optimizer.step()
return dqn_loss.item(), grad_norm.item()
def convert_state(self, state):
# Return imput image as a tensor
# return torch.from_numpy((np.array(state)/255).astype(np.float32)).unsqueeze(0).to(device)
# return (np.array(state)/255).astype(np.float32)
return state
def run(self):
self.best_reward = 0
self.best_avg_rewards = 0
self.rewards = []
self.avg_rewards = []
if not params["train_from_scratch"]:
print("Keep training from previous run.")
else:
self.min_episode = 0
print("Train from scratch.")
if params["do_train"]:
sign = lambda x: bool(x > 0) - bool(x < 0)
state = np.zeros(shape=params["state_shape"], dtype=np.uint8)
obs, info = env.reset()
self.lives = info['lives']
state = self.convert_state(obs)
episode_reward = 0
episode_len = 0
episode_loss , episode_g_norm = 0, 0
beta = params["beta"]
episode = self.min_episode + 1
for step in range(1, params["max_steps"] + 1):
episode_len += 1
action = agent.choose_action(state)
next_obs, reward, terminated, truncated, info = env.step(action)
# Click FIRE if definced also when losing live
if game_params['FIRE_TO_START'] and info['lives'] < self.lives:
self.lives = info['lives']
next_obs, reward, terminated, truncated, _ = env.step(1)
done = terminated or truncated
# For pacman, optimize eating fruits and not other rewards to focus on finish the game
if game_params['OPT_FRUITS']:
#if reward == 0: reward = -1 # Penalize no score to avoid staying at one place and do nothing
if info['lives'] < self.lives: reward = -100 # penalize losing life
if reward > 50: reward = 0 # Reward only on eating fruits and vitamins
if done: reward = info['lives'] * 100 # Add reward for every life esist
self.lives = info['lives']
next_state = self.convert_state(next_obs)
r = sign(reward)
agent.store(state, action, r, next_state, done)
episode_reward += reward
if step % params["train_period"] == 0:
beta = min(1.0, params["beta"] + step * (1.0 - params["beta"]) / params["final_annealing_beta_steps"])
loss, g_norm = agent.train(beta)
else:
loss, g_norm = 0, 0
episode_loss += loss
episode_g_norm += g_norm
if step % params["hard_update_freq"] == 0:
agent.hard_update_target_network()
# env.render()
state = next_state
if episode_len == params["max_frames_per_episode"]:
done = True
if done:
self.plot_and_save(episode,
episode_reward,
episode_loss / episode_len * params["train_period"],
episode_g_norm / episode_len * params["train_period"],
step,
beta,
episode_len,
False)
episode += 1
obs, info = env.reset()
self.lives = info['lives']
state = self.convert_state(obs)
episode_reward = 0
episode_len = 0
episode_loss = 0
episode_g_norm = 0
# save the model
self.plot_and_save(episode,
episode_reward,
episode_loss / episode_len * params["train_period"],
episode_g_norm / episode_len * params["train_period"],
step,
beta,
episode_len,
show_result=True)
def ready_to_play(self):
self.online_model.eval()
def get_n_step_returns(self):
reward, next_state, done = self.n_step_buffer[-1][-3:]
for transition in reversed(list(self.n_step_buffer)[:-1]):
r, n_s, d = transition[-3:]
reward = r + self.gamma * reward * (1 - d)
next_state, done = (n_s, d) if d else (next_state, done)
return reward, next_state, done