Analyzing Trace Data Using Apache Spark¶
This is a demo for using Apache Spark to analyze network trace data. The demo is a good example for using Apache Spark and go through different angles of it including optimizing the processing to a cluster of nodes. It uses:
- File reader with partitions
- Data frame creation
- Filter and map functions
- Window functions
- UDF functions
- Graph plot
The Trace File
The trace data read from a file that contains information on how a router handled each packet. In particular it looks at metadata that represents how flow table and NBAR2 process each packet.
The Analysis
The analysis performs few tasks:
- Parse packets from a file
- Create a data frame with the packet info
- Create network 5-tuple for the packets
- Generate histograms and graphs
The analysis written in Jupyter Notebook PySpark Shell over Apache Spark running on top of 2 nodes Hadoop cluster with Yarn.
About me¶
I'm a system/software architect, working for the Core Software Group at Cisco Systems. Having many years of experience in software development, management, and architecture. I was working on various network services products in the areas of security, media, application recognition, visibility, and control. I'm holding a Master of Science degree in electrical engineering and business management from Tel Aviv University and always likes to learn and experiment with new technologies and ideas. More can be found in my website: http://nir.bendvora.com/Work
Importing the necessary Python libraries¶
# Show / Hide code Button
from IPython.display import HTML
HTML('''<button class="toggle">Show/Hide Code</button>''')
import re
from pyspark.sql import Row
from pyspark.sql.types import *
from pyspark.sql import functions as F
from pyspark.sql.window import Window
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import sys
%matplotlib notebook
sc
Spark UI Environment¶
HTML('''<a href="./sparkEnvironment.JPG" target="_blank"><img src="./sparkEnvironment.JPG"
alt="Spark Environment" width="500" height="245">
</a>Click for full size''')
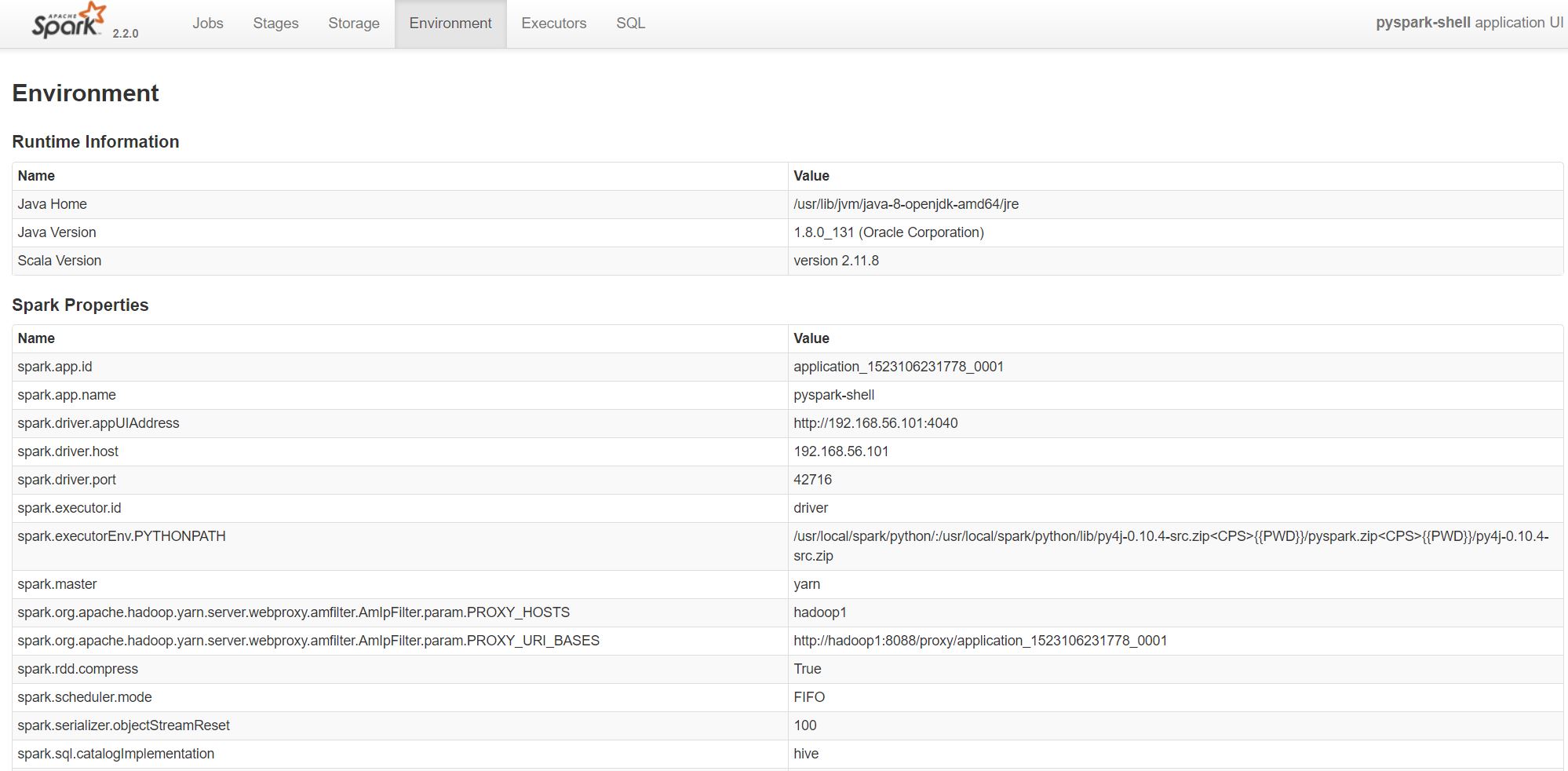 Click for full size
Click for full size
# Config to display all pandas columns
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1000)
Reading the Trace file¶
The trace file placed in HDFS "nirbd_trace_nov_8.txt". Reading the file using the newAPIHadoopFile that split the file into partitions based on the delimiter. Create 50 RDD partitions.
# Show / Hide code Button
HTML('''<button class="toggle">Show/Hide Code</button>''')
trace = sc.newAPIHadoopFile(
'hdfs://hadoop1:54310/user/hduser/trace_analysis/nirbd_trace_nov_8.txt',
'org.apache.hadoop.mapreduce.lib.input.TextInputFormat',
'org.apache.hadoop.io.LongWritable',
'org.apache.hadoop.io.Text',
conf={'textinputformat.record.delimiter': 'Packet: '}).partitionBy(50)
print "Check partition result:\n Num Partitions=", trace.getNumPartitions(), \
"\n Partitioner=", trace.partitioner, \
"\n Partition Function=", trace.partitioner.partitionFunc
trace_values = trace.values()
print "Number of packets read: ", trace_values.count()
Filter valide packets¶
Use map functtion to filter valid packets. It applies the filter for every partition but doesn't preserve the parent partitioning
# Show / Hide code Button
HTML('''<button class="toggle">Show/Hide Code</button>''')
def filter_valid(r):
if re.match("^\d+\s+CBUG ID",r): return True
else: return False
valid = trace_values.filter(filter_valid)
print "Num Partitions=", valid.getNumPartitions(), \
"\nPartitioner=", valid.partitioner, \
"\nNumber of valid packets:", valid.count()
#t = valid.take(10)
Parsing packets¶
Extracting relevant information using regex on each packet text. Applyting map to every packet RDD. Create a data frame Row from every packet
# Show / Hide code Button
HTML('''<button class="toggle">Show/Hide Code</button>''')
def parse_pkt(pkt):
pkt_num = int(re.match("^(\d+)\s+CBUG ID",pkt).group(1))
r = re.search("Summary\n Input : (.*)\n Output : (.*)\n State :.*\n Timestamp\n Start : (\d+) ns", pkt)
in_if = r.group(1)
out_if = r.group(2)
ts_start = long(r.group(3))
r = re.search(" Feature: CFT\n API.*\n.*\n.*\n.*\n direction : (.*)\n.*\n.*\n.*\n.*\n.*\n cft_l3_payload_size : (\d+)\n.*\n.*\n tuple.src_ip : (.*)\n tuple.dst_ip : (.*)\n tuple.src_port : (\d+)\n tuple.dst_port : (\d+)\n tuple.vrfid : (\d+)\n tuple.l4_protocol : (.*)\n tuple.l3_protocol : (.*)\n", pkt)
direction = r.group(1)
size = int(r.group(2))
src_ip = r.group(3)
dst_ip = r.group(4)
src_port = r.group(5)
dst_port = r.group(6)
vrf = int(r.group(7))
protocol = r.group(8)
ip_ver = r.group(9)
r = re.search(" Feature: NBAR\n Packet number in flow: (.*)\n Classification state: (.*)\n Classification name: (.*)\n Classification ID: .*\n Number of matched sub-classifications: (\d+)\n Number of extracted fields: (\d+)\n", pkt)
if r.group(1) == "N/A": pkt_in_flow = -1
else: pkt_in_flow = int(r.group(1))
cls_state = r.group(2)
app = r.group(3)
num_subcls = int(r.group(4))
num_exfld = int(r.group(5))
r = re.search("IPV4_INPUT_STILE_LEGACY\n Lapsed time : (\d+) ns", pkt)
if r == None: nbar_in_cycles = -1
else: nbar_in_cycles = int(r.group(1))
r = re.search("IPV4_OUTPUT_STILE_LEGACY\n Lapsed time : (\d+) ns", pkt)
if r == None: nbar_out_cycles = -1
else: nbar_out_cycles = int(r.group(1))
return Row(pkt_num=pkt_num, in_if=in_if, out_if=out_if, ts_start=ts_start,
direction=direction, size=size, src_ip=src_ip, dst_ip=dst_ip, src_port=src_port, dst_port=dst_port,
vrf=vrf, protocol=protocol, ip_ver=ip_ver,
pkt_in_flow=pkt_in_flow, cls_state=cls_state, app=app, num_subcls=num_subcls, num_exfld=num_exfld,
nbar_in_cycles=nbar_in_cycles, nbar_out_cycles=nbar_out_cycles)
#parse_pkt(t[1])
Parse the entire trace file¶
Caching the result data frame in memory for next usage
# Show / Hide code Button
HTML('''<button class="toggle">Show/Hide Code</button>''')
pkts = valid.map(parse_pkt).toDF() \
.select('pkt_num', 'ts_start', 'protocol', 'src_ip', 'dst_ip', 'src_port', 'dst_port', 'size', 'in_if',
'out_if', 'app', 'cls_state', 'pkt_in_flow', 'nbar_in_cycles', 'nbar_out_cycles',
'num_subcls', 'num_exfld' ,'ip_ver', 'direction', 'vrf') \
.cache()
pkts Schema¶
pkts.printSchema()
#### Show unique applications in the trace
# Show / Hide code Button
HTML('''<button class="toggle">Show/Hide Code</button>''')
# Unique Applications
pkts.select('app').distinct().orderBy('app').toPandas()
Display packets where packet in flow > 100¶
# Show / Hide code Button
HTML('''<button class="toggle">Show/Hide Code</button>''')
pkts.where(pkts['pkt_in_flow']>100).orderBy('pkt_in_flow', ascending=False).limit(10).toPandas()
Display for each application the max non bypass packet number¶
# Show / Hide code Button
HTML('''<button class="toggle">Show/Hide Code</button>''')
pkts.filter(pkts['pkt_in_flow']>0).orderBy('pkt_in_flow', ascending=False).groupBy('app').agg(F.max('pkt_in_flow').alias('max non-bypass pkts')).toPandas()
Display for each application the 2 packets with max non-bypass packets¶
Using a window to generate the result
# Show / Hide code Button
HTML('''<button class="toggle">Show/Hide Code</button>''')
# Show NUM_PER_APP of packets with max packets_in_flow where pkt_in_flow > MIN_PKT_FLOW
NUM_PER_APP = 2
MIN_PKT_FLOW = 10
window = Window.partitionBy(pkts['app']).orderBy(pkts['pkt_in_flow'].desc())
pkts.where(pkts['pkt_in_flow']>MIN_PKT_FLOW).orderBy('app').select(F.col('*'), F.row_number().over(window) \
.alias('row_number')).where(F.col('row_number') <= NUM_PER_APP).drop('row_number').limit(20).toPandas()
Plot the packet size, NBAR2 in/out cycles histograms¶
Generate the histogram and bring the result to the driver to plot the histogram
# Show / Hide code Button
HTML('''<button class="toggle">Show/Hide Code</button>''')
# Function to plot an histogram of a dataframe column
# The histogram heavy lifting is done using spark DF, the result is plotted as a bar chart
def plot_hist(df, col, nbins=50, range=None, title="", xlabel="Bin", ylabel="Count"):
if range==None:
maxp = df.agg(F.max(col).alias('maxhist')).collect()[0]['maxhist']
step = 1.0*maxp/nbins
bins = np.arange(0,maxp+step,step)
else:
step = 1.0*(range[1]-range[0])/nbins
bins = np.arange(range[0]-step, range[1]+step, step)
histogram = df.select(col).rdd.flatMap(lambda x: x).histogram(list(bins))
fig, ax = fig, ax = plt.subplots(figsize=(7, 5))
plt.bar(histogram[0][:-1], histogram[1], align='center', width=step, color='steelblue', edgecolor=['k']*len(histogram[1]))
ax.xaxis.grid(True, linestyle=':', linewidth=0.5)
ax.yaxis.grid(True, linestyle=':', linewidth=0.5)
#locs, labs = plt.xticks()
#plt.xticks(locs[::nbins/10], labs[::nbins/10], rotation=0)
plt.title(title)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.tight_layout()
plot_hist(pkts, 'size', nbins=50, title="Packet Size Histogram", xlabel="Packet Size [B]", ylabel="Count")
plot_hist(pkts, 'nbar_in_cycles', nbins=50, title="Input Cycles Histogram", xlabel="Cycles [ns]", ylabel="Count")
plot_hist(pkts, 'nbar_out_cycles', nbins=50, title="Output Cycles Histogram", xlabel="Cycles [ns]", ylabel="Count")



Add the flow each packet belongs to¶
This is done using a UDF function
# Show / Hide code Button
HTML('''<button class="toggle">Show/Hide Code</button>''')
# normalized flow for each packet
def normalize_flow(src_ip, dst_ip, src_port, dst_port, prot, vrf):
if src_ip > dst_ip:
return [(src_ip, dst_ip, src_port, dst_port, prot, vrf)]
else:
return [(dst_ip, src_ip, dst_port, src_port, prot, vrf)]
nflow_schema = ArrayType(StructType([
StructField("nsrc_ip", StringType(), False),
StructField("ndst_ip", StringType(), False),
StructField("nsrc_port", StringType(), False),
StructField("ndst_port", StringType(), False),
StructField("nprot", StringType(), False),
StructField("nvrf", IntegerType(), False)
]))
normalized_flow_udf = F.udf(normalize_flow, nflow_schema)
pkts_f = pkts.withColumn('norm-flow', normalized_flow_udf('src_ip', 'dst_ip', 'src_port', 'dst_port', 'protocol', 'vrf'))
# Assign a unique incremental number for each flow
nf_window = Window.partitionBy().orderBy('norm-flow')
norm_flow_id = pkts_f.select('norm-flow').dropDuplicates().select(F.col('*'), (F.row_number().over(nf_window) -1).alias('FID'))
# Assign the flow ID to each packet
pkts_fid = pkts_f.join(norm_flow_id, 'norm-flow').drop('norm-flow')
pkts_fid.limit(10).toPandas()
Display all packets belong to flow number 0¶
# Show / Hide code Button
HTML('''<button class="toggle">Show/Hide Code</button>''')
pkts_fid.where(pkts_fid['FID'] == 0).toPandas()
Calculate the number of packets, Inter Packet Gap (IPG) and direction for each packet in a flow¶
# Show / Hide code Button
HTML('''<button class="toggle">Show/Hide Code</button>''')
# For each flow calculate, number of packets, pkt in flow, is_initiator, IPG
fp_window = Window.partitionBy('FID').orderBy('ts_start')
pkts_flow = pkts_fid.select(F.col('*'),
F.row_number().over(fp_window).alias('pkt_num_in_flow'),
((pkts_fid['ts_start'] - F.lag(pkts_fid['ts_start']).over(fp_window))).alias('IPG'),
((pkts_fid['src_ip']==F.first(pkts_fid['src_ip']).over(fp_window)) & (pkts_fid['src_port']==F.first('src_port').over(fp_window))).alias('Initiator')) \
.cache()
pkts_flow.limit(20).toPandas()
Plot the Inter Packet Gap (IPG) Histogram¶
# Show / Hide code Button
HTML('''<button class="toggle">Show/Hide Code</button>''')
plot_hist(pkts_flow, 'IPG', nbins=50, title="IPG Histogram", xlabel="IPG [ns]", ylabel="Count", range=[0,40000])

Spark UI DAG¶
This is the Spark UI DAG for the last histogram that shows the flow of the data. It contains three stages each with few map functions.
HTML('''<a href="./jobDAG.jpg" target="_blank"><img src="./jobDAG.jpg"
alt="Spark Environment" width="500" height="644">
</a>Click for full size''')
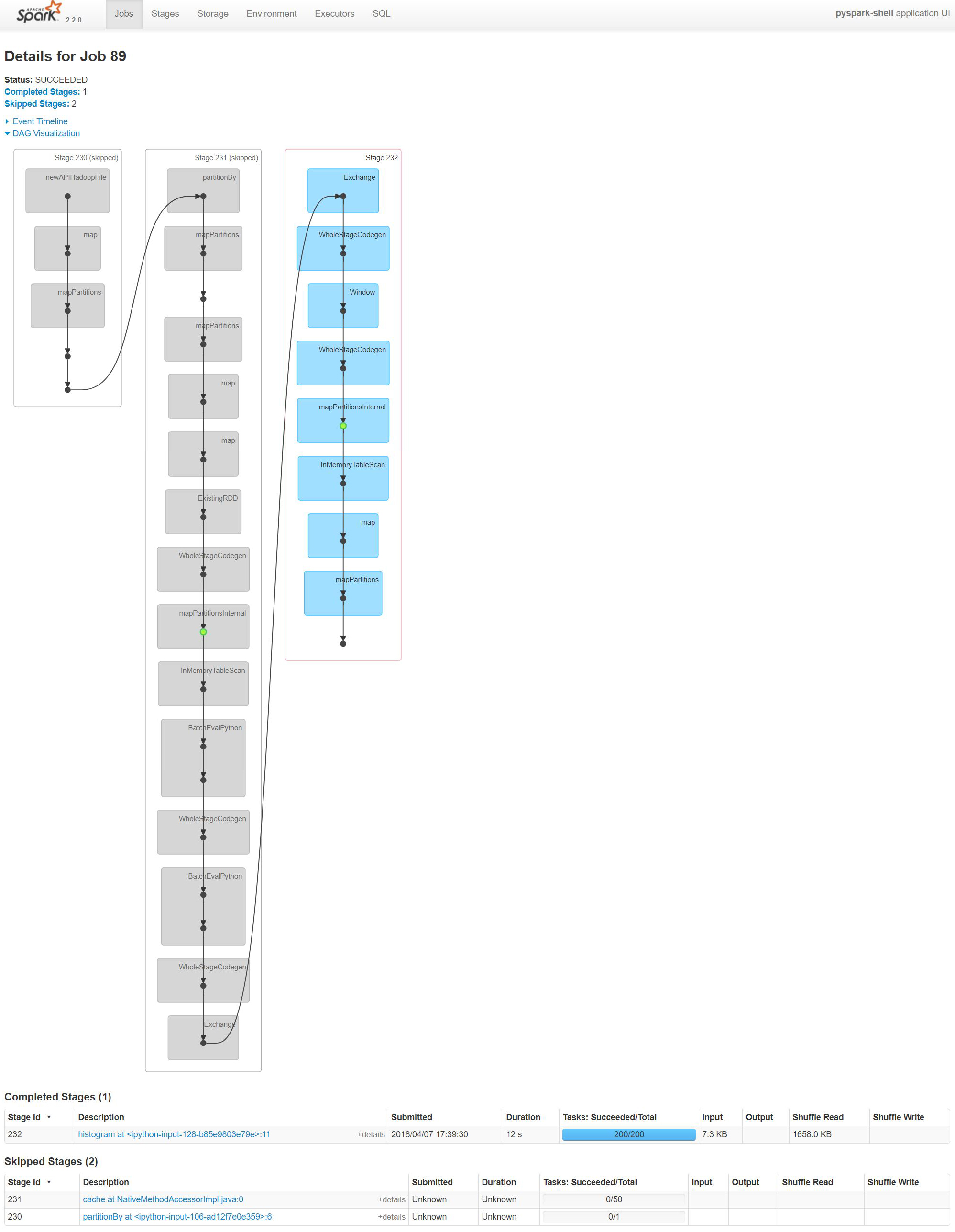 Click for full size
Click for full size
# TBD: Add to nbconvert full html as a script
HTML('''
<style>
button {
background-color: #4CAF50;
border: none;
color: #FFF;
padding: 5px 20px;
text-align: center;
text-decoration: none;
display: inline-block;
font-size: 16px;
}
button:hover {
box-shadow: 0 8px 16px 0 rgba(0,0,0,0.2), 0 6px 20px 0 rgba(0,0,0,0.19);
</style>
<script>
$( document ).ready(function(){
$('.toggle').parent().parent().parent().parent().prev().hide();
$('div.input').hide();
$('.pre_code').hide();
});
$('.toggle').click(function(){
e1 = $(this).parent().parent().parent().parent().parent().next().find('.input');
if (e1.is(":visible") == true) {
e1.hide('500');//hide parent
} else {
e1.show('500');//hide parent
}
e2 = $(this).parent().parent().parent().parent().parent().next().find('.pre_code');
if (e2.is(":visible") == true) {
e2.hide('500');//hide parent
} else {
e2.show('500');//hide parent
}
});
</script>
<div class="toggle"></div>
''')